珍しく技術ブログっぽいことをやってみる記事。
PaLM2とは?
本家ページ:https://japan.googleblog.com/2023/05/palm-2.html
2023年5月11日にGoogleが発表した大規模言語モデルです。Google Bardという名前はよく聞きますが、Google BardのベースになったのがPaLM2という大規模言語モデルです。
2022年12月にOpenAIがChatGPTを公開したことに対抗すべく、2月頭にGoogleがBardと名付けた会話型AIの検索機能について発表します。 この時にはLaMDAと呼ばれるLLMが使われていますが、内部でも批判が出るほど性能が出ているわけでもなく、完璧なパニックとさえ言われてしまいます。
その後3月14日にOpenAIがGPT4を発表し、それと同時にMicrosoftがBingへのGPT4適用を発表します。GPT4の性能は日本語での司法試験も受かるわ画像も入力に出来るわプログラムも出来るわで、かなりセンセーショナルな発表だったことは記憶に新しいです。
GoogleはLaMDAではなくPaLMと呼ばれるLLMを2022年ごろに発表はしており、GPT3.0より高性能であると論文では書かれてますが、いかんせんGPT3.5やGPT4が出てきてしまってますので、社内では色々と対応を迫られていたのでしょう。研究者の方お疲れ様です・・・。
そんな流れで出来たのがPaLM2なんですね。PaLM2とGPT4を比較すると学習トークン数では圧倒的に後者が上ということもあり、さすがに性能的にはGPT4のほうに軍配が上がるようです。ただ、学習データの質に違いがあるようで、Reddit(2ちゃん)などは意図的に学習データから抜いており、ヘイトスピーチのようなものは出力されづらい仕組みになっている点はGPT4より勝るのかもしれないですね。
なんでPaLMなの?
いやだって、会社の人みんなAzure OpneAIだGPTだ言うから、逆張りしてんのよ・・・。
というのは半分冗談として、LLMが使いこなせるのは頭のよい人類の一部とIT企業の一部だと思っているので、私個人の意見としてはもう2~3か月もしたら減滅期に入るんではないかなと思っています。(口に出して言ったら何こいつみたいな目で見られるので言わないけど。)
将来像としては、ビジネスで一部の人がOfficeに組み込まれたLLMを利用し、世界の大多数が検索でGoogleのLLMを使う、みたいな。そんな構図になると考えます。GoogleのLLMはもちろんGoogle検索そのものです。人々の欲望は検索に現れるので、ユーザのニーズに適したLLMの開発はGoogleのほうに分があるんではなかろうかと、そう思うわけです。
使いこなせるのは一部の人と書きましたが、今LLMを使おうと躍起になっている人達は「LLMを使えない側」の人達が多い感触です。そしてそういう人達が気にするのは往々にしてセキュリティやガバナンス。そして活用PJの推進役はその人達の部下である「LLMを使えない側の人達」が推進する。何に使えるか分からないけど頑張ってセキュリティとかガバナンスとかちゃんとやって、ってなると推進役のモチベーションも落ちますから、結局は使えないね・・・の結論になるのがほぼほぼ多数になるんじゃなかろうか・・。って感じです。
あ、ちょっと愚痴が入ってしまった。
本題:PaLM2 for Chatを触ってみた
PaLM for ChatはGCPのVertexAIで使えるモデルですね。
折角なので、ちょっとしたGUI作ってWebアプリ的に動かしてみようぜというモチベーションで試してみました。
↓のようにテキストボックスにメッセージを入れるとPaLM2から結果を返してくれるようなすごくシンプルなものです。

私が作ったコードは以下にアップロードしていますので、興味があれば。
https://github.com/hiro-maro-1118/GooglePalmTest.git準備作業自体はこちらに譲る。
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.gitで落としてきたコード群の中に、「python-docs-samples\generative_ai\chat.py」というファイルがあるので、基本的にはそれを使います。
下はchat.pyを修正したもの。
from vertexai.preview.language_models import ChatModel, InputOutputTextPair
from flask import Flask,render_template,request,jsonify
app = Flask(__name__)
def science_tutoring(user_message,temperature: float = 0.2) -> None:
chat_model = ChatModel.from_pretrained("chat-bison@001")
# TODO developer - override these parameters as needed:
parameters = {
"temperature": temperature, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.95, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
# chat = chat_model.start_chat(
# context="My name is Miles. You are an astronomer, knowledgeable about the solar system.",
# examples=[
# InputOutputTextPair(
# input_text="How many moons does Mars have?",
# output_text="The planet Mars has two moons, Phobos and Deimos.",
# ),
# ],
# )
chat = chat_model.start_chat(
context="My name is Miles. You are an individual with abundant business ideas and a strong knowledge of business.",
examples=[
InputOutputTextPair(
input_text = "Please tell me how to develop future business ideas based on the latest technology trends and market demand.",
output_text = "It is important to thoroughly research the latest technology trends and market demand, and develop new products or services based on them. Additionally, by gathering customer feedback and analyzing competitors, you can generate sustainable and differentiated business ideas. Furthermore, it is crucial to articulate the ideas into concrete business plans and adopt strategic marketing approaches that consider market needs and competitive landscape.",
),
InputOutputTextPair(
input_text = "Please advise on effective strategies for entering new markets.",
output_text = "When entering a new market, start by conducting market research and analyzing target customers and competitors. Then, clarify your company's strengths and unique selling points, and provide products or services that meet customer needs. Additionally, consider competitive pricing and deploy effective marketing campaigns to facilitate market entry. Also, explore strategic initiatives suitable for the market environment, such as partnerships and establishing distribution channels.",
),
],
)
response = chat.send_message(
# "How many planets are there in the solar system?", **parameters
user_message, **parameters
)
print(f"Response from Model: {response.text}")
# [END aiplatform_sdk_chat]
return response.text
@app.route('/')
def index():
return render_template('index.html')
@app.route('/process_message', methods=['POST'])
def process_message():
user_message = request.json.get('message')
# Call the science_tutoring function with the user message
bot_response = science_tutoring(user_message)
# Return the bot response as a JSON object
return jsonify({'response': bot_response})
if __name__ == "__main__":
app.run()API(なのか?)で指定できるパラメータ
parameters = {
"temperature": temperature, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.95, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}指定できるパラメータ。詳細は本家のページを見てほしいですが、ざっくり以下の意味を持ちます。
temperature:トークン選択のランダム性の度合いを制御。0だと確率が一番高いものが選択される。0.2くらいがよい。
max_output_tokens:1 つのプロンプトから出力されるテキストの最大量。トークンは約 4 文字です。デフォルト値は 256 です。
top_p:出力用トークンの選択方法(確率値ベース)
top_k:出力用トークンの選択方法(確率の順位ベース)
contextパラメータについて
chat = chat_model.start_chat(
context="My name is Miles. You are an individual with abundant business ideas and a strong knowledge of business.",
examples=[
InputOutputTextPair(
input_text = "Please tell me how to develop future business ideas based on the latest technology trends and market demand.",
output_text = "It is important to thoroughly research the latest technology trends and market demand, and develop new products or services based on them. Additionally, by gathering customer feedback and analyzing competitors, you can generate sustainable and differentiated business ideas. Furthermore, it is crucial to articulate the ideas into concrete business plans and adopt strategic marketing approaches that consider market needs and competitive landscape.",
),
InputOutputTextPair(
input_text = "Please advise on effective strategies for entering new markets.",
output_text = "When entering a new market, start by conducting market research and analyzing target customers and competitors. Then, clarify your company's strengths and unique selling points, and provide products or services that meet customer needs. Additionally, consider competitive pricing and deploy effective marketing campaigns to facilitate market entry. Also, explore strategic initiatives suitable for the market environment, such as partnerships and establishing distribution channels.",
),
],
)context:モデルがどのように応答すべきかを指定するものです。たとえば、「このコードを説明して」のように、モデルが使用できる言葉や使用できない言葉、沿うべきトピックや避けるべきトピック、応答の形式を指定します。コンテキストは、モデルにリクエストを送信するたびに適用されます。
GCPの原文ママですが、これがちょっとよくわからなかったので少し試してみました。
context="My name is Miles. You are an astronomer, knowledgeable about the solar system."を指定して、「Who is Shohei Ohtani ?」と入れると「“I am not sure about that. I am an astronomer, knowledgeable about the solar system.”」
と帰ってくる。天文学者のロールプレイをやってるみたいです。
context="My name is Miles. You are an individual with abundant business ideas and a strong knowledge of business.",自分をビジネスマンだと思い込ませるコンテキストでも試してみました。

演じてくれてます。演じてくれてます。
追加でもう一例。

さすがビジネスマン。MLBにも長けてますね。
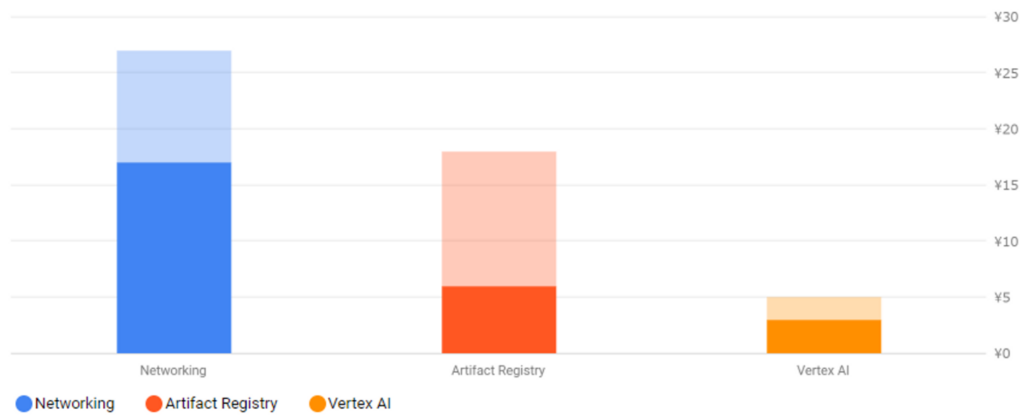
課金額
テスト含めて大体20~30ほど実行したかと思いますが、大体30円くらいでした。
Artifact Registryは昔のごみが残ってるだけだと思うので忘れて・・・。