https://signate.jp/competitions/264/data
のデータサイズがお手頃感があるので、これを使って前回の記事の一番最後に書いたLightGBMの特徴について調べてみる。
と高をくくっていたら、特徴量抽出に3日ほどかかりましたとさ・・・実装力のなさが顕著に出た。
display(len(target_df.columns))
>128元データのカラム数は17だったことを考えると、ちょっと頑張りました。(これでもいくつかのカラムは捨てた)
というわけで、特徴量を作った後からのコーディング。
lightGBM特徴1と2:null変換不要+カテゴリ変数変換不要
import lightgbm
X,Y = target_df.drop(['id','賃料'],axis=1),target_df['賃料']
#categoryにしたりbool値にしたりしないと怒られた
X[['所在地','間取り','方角','建物構造','1st_line', '1st_station', '2nd_line', '2nd_station','3rd_line', '3rd_station']] = X[['所在地','間取り','方角','建物構造','1st_line', '1st_station', '2nd_line', '2nd_station','3rd_line', '3rd_station']].astype('category')
X[['2nd_bus_flg','3rd_bus_flg']] = X[['2nd_bus_flg','3rd_bus_flg']].astype('category')
X_train,X_val,y_train,y_val = train_test_split(X,Y)
lg_train = lightgbm.Dataset(X_train,y_train)
lg_eval = lightgbm.Dataset(X_val,y_val)
params={'objective':'regression','seed':71,'verbose':0,'metrics':'rmse'}
model = lightgbm.train(params,lg_train,num_boost_round=100,valid_names=['tran','test'],valid_sets=[lg_train,lg_eval])コードはこれだけ。学習時間は3~4分程度ですぐに完了。
pred = model.predict(X_val)
np.sqrt(mean_squared_error(pred,y_val))
>25358.04181849675とりあえずテストデータも推論してsubmit。
400位なので軽くやっただけでも上位25%になりました。
null値はそのまま、カテゴリ変数もそのまま、なので前回の記事の一番最後に書いた1と2については十分証明できたかなと。
lightGBM特徴3:特徴量のスケーリングが不要

見づらい!けどスケールが全然あっていないことがわかる。つまりは、スケーリングしなくても性能が出るということ。
まぁ、性能が出るというよりはアルゴリズム的にスケーリングする意味がないといったほうが正しいか。
lightGBM特徴4:feature_importanceがわかる
importance = pd.DataFrame(model.feature_importance(), index=X_train.columns, columns=['importance'])
importance.sort_values(by='importance',ascending=False)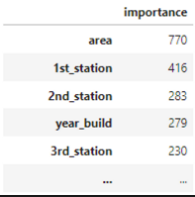
うーん、回帰であればsklearnでもfeature importanceは出力できるから、そこまでのメリットというわけではなさそうな?
https://scikit-learn.org/stable/modules/generated/sklearn.inspection.permutation_importance.html
とはいえ、特徴量が一旦できた後に試してみて、重要な特徴量って何かな?って簡単に見れるのはいいよね。
上の図を見た感じでも、人間の感覚ともある程度一致しそう。
area・・家が建ってる場所、1st_station:最寄り駅1の名前、2nd_station:最寄り駅2の名前 year_build・・築年数
って感じなので、物件探す時に見るところと大体あってるよね~。
lightGBMの特徴5:性能が出やすい⇒割愛
lightGBMの特徴6:比較的大きいデータも高速に扱える
https://alphaimpact.co.jp/downloads/pydata20190927.pdf
では200GBなどのサイズに言及されていることから、20~30MBぽっちではあまり恩恵を受けられていない模様。
ドキュメントにある通り20MB程度のデータであれば、CatBoostを使うとよいみたいだね。
lightGBMの特徴7:過去の実績からハイパーパラメータの勘所がある
パラメータを流用してもそれなりに精度が出るのかな?
https://zenn.dev/nishimoto/articles/815e841b188b87
https://github.com/nyanp/nyaggle/blob/master/nyaggle/hyper_parameters/lightgbm.py
のあたりを参考にパラメータをいじってみる
params = {
'objective': 'regression',
'metric': 'rmse',
'seed':71,
'boosting_type': 'gbdt', # default = 'gbdt'
'num_leaves': 63, # default = 31,
'learning_rate': 0.01, # default = 0.1
'feature_fraction': 0.8, # default = 1.0
'bagging_freq': 1, # default = 0
'bagging_fraction': 0.8, # default = 1.0
'random_state': 0, # default = None
}
#結果
np.sqrt(mean_squared_error(pred,y_val))
前>25358.04181849675
後>18438.82223386077430%くらい良くなってるので優秀だね。
ただ、リーダボードはちょろっと順位が上がったくらい。

Kaggle本や色々調べると、「まずはこれを調べるべき」という指針が乗っているので、情報が探しやすいという利点は大きいね。
という感じで触って考察して理解して、をやってみました。