年末に受けてきますが、なかなか勉強の時間が取れません。はい、いいわけです。
Whizlabの問題集や模擬試験からGCPの出題点をピックアップして整理する記事にしてアウトプットをしてみる。
Whizlabの問題はおそらく実際に出るような問題でもなさそうなので、どう扱うかが微妙なところ。
Examtopicもやってみてはいるんだけど、Vertext AIじゃなくてAI Platformで止まっているのがなんとも・・・。
Loss Curve
曲線のパターンを見て学習時に何が起きているのかを推測する。
| # | 事象 | 疑う事象 | 説明 |
|---|---|---|---|
| 1 | 常に振動している | 予測が出来ていない 学習率が大きすぎる可能性がある | 予測が出来ていないということは、モデルがあまりよろしくないということ。まずは収束するモデルを作ってチューニングをしていきたい。 学習率が大きいと重みの更新時に振動をおこしてしまうのは、機械学習の本で口酸っぱく言われているが、そのこと。重みが振動をおこしてしまっているのでLoss Curveも振動してしまっている。 |
| 2 | 急に損失が増える | 学習データに異常がある(欠損値値) ロジック誤り(0除算) | 基本的にラベルとの差をなくしていく計算をしていくので、欠損値があると差がうまく取れなくなる場合がある。0除算も含めプログラムの見直しが必要。 PytorchとかTensorFlowならそんなことはあまりないとは思うけど・・・。 |
| 3 | 損失が減少しているがRecallがPrecisionが0 | ・True Positiveが0(全く当てれていない) ・閾値が高すぎる可能性がある | Recall(TP/TP+FN)、再現率、Precision(TP/TP+FP)、適合率。ラベルが不均衡なデータで起きやすい。正を正とする閾値が高い(例えば、モデルの予測が0.8を超えたら正とするなど)場合は大体Negative側によるので、そうなりやすい。CrossEntropyは変じゃないのに・・・とかいう場合はこれ。 |
| 4 | 損失が減少したあとに振動 | ・入力がループしている(パターンがあまりない) | 私はあまり見たことがないパターン。(変なのは過学習起こして急上昇するパターンが主) ロジックミスで同じバッチを何回も学習させている可能性がある。限界まで学習して、もうどうしようもなくなって振動をせざるをえない、みたいな。 |
メトリックの使いどころ
どういった観点で損失関数を選択するか?
対象は、MAE(平均絶対誤差)、RMSE(二乗平均平方誤差)、RMSLE(二乗平均大数平方誤差)、MSE(二乗平均誤差)
誤差のペナルティをどうしたいか?によって選択肢が変わる。
MSE > RMSLE > MAE
の順で誤差にペナルティーが課される。
【外れ値に対してロバストにしたい】
MAE
【誤差ペナルティに敏感になりたい】
MSE
【比率で差をみたい】
RMSLE (対数なので、予測が負の値の場合は使えない。∞になっちゃう・・・!)
DataLineage
聴いたことがなかった言葉。試験受けようとするとこういうのを知れるからいいよね。
データマネジメントに関する言葉という認識。
データの信頼性を示すもので、「どのような経路で取得、作成されたデータか?」を示す概念。
異常時のトレースが用意に出来て、データの信頼性も向上して、変更の影響もそこそこ理解しやすくなる、みたいなものらしい。
スキューとドリフト
どちらもデータの分布によって学習・推論に影響を与える概念。
スキュー:純粋なデータの分布が偏っていること。統計を取ると歪なデータ分布をしている
ドリフト:時間経過でデータの分布が変わること。学習モデルはある特定の分布について最適化しているから、その分布が変わってくると予測が十分に出来なくなるよね。ということ。
モデルの量子化
重みを32bit/16bitから8bitにする。精度はほぼそのままで計算量を軽くすること。
量子化には色々種類があるらしい。
| 学習済みモデルの量子化 | モデルを32bitから16bitに変換。 TensorFlowやPytorchのライブラリでは簡単にできる。 | とりあえず軽くしてみたいぜ! って場合はこれかな? |
| ダイナミックレンジ量子化 | モデルの精度は少し低くなるが、1/4程度にモデルを圧縮することが出来る | サーバで動かしたいけどそこまで大きなモデルはちょっと・・・みたいなときか |
| 整数量子化 | 制度は下がるが、すごく軽くなる | モバイル、モバイル、モバイル |
| 量子化認識トレーニング | 学習中に量子化できる。 | 損失曲線が描けるということなので、(前はないが)量子化前後の精度に対する期待値のずれがない |
Tensorflowの分散学習
メモリが足りないなどの場合は分散学習をする。
基本的な動き
・データが分割されてレプリカはそれぞれのデータで学習する
・パラメータを更新
・パラメータを同期
(レプリカとは、並行して実行されるモデルのインスタンス)
Strategyは大きく4つ
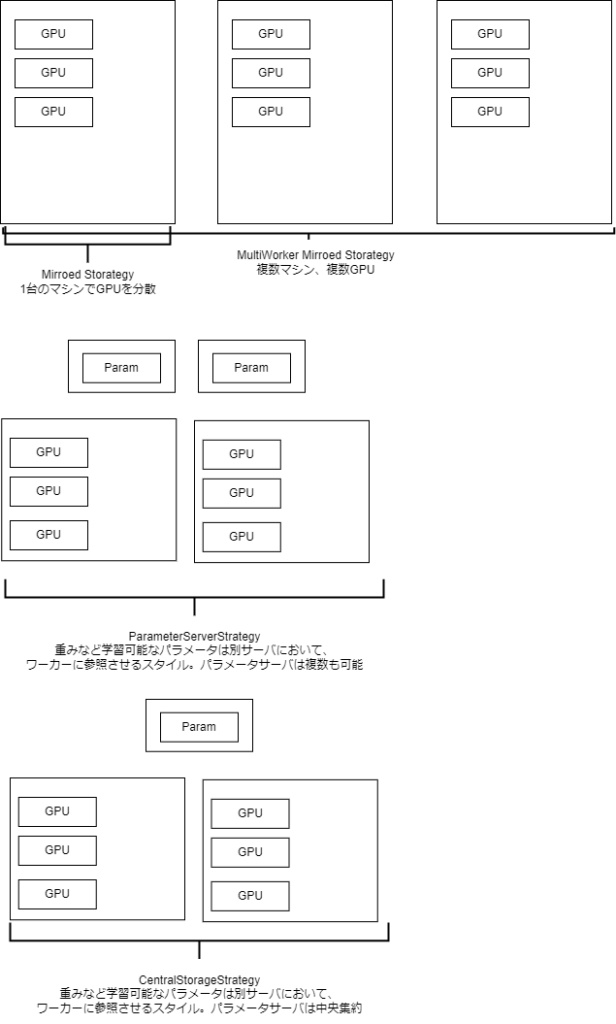
ワーカーとかパラメータサーバはどうやって制御するか?
TF_CONFIGというものがある。
clusterとtaskを定義したコンフィグファイルを各ノードに置いてやる。
そのノードがなんの役割をしているサーバなのか?と全体から見て何番目のノードとして割り当てられているのか?
を示しているのがTF_CONFIG。
何番目のノードとして割り当てられているか?を指定しておくことで、実機レイヤでの「workerの入れ替えを楽にできる。